Web Application Security for DevOps: Site and Origin Dynamics and Cross-Site Request Forgery
Tags:


This is a continuation of the series on web application security. If you haven't already read through part 1, this is a good time to go back. If not, let's move on and answer the question left hanging during our last installment: how do browsers know which site set the cookies in the first place? And what constitutes the same site?
Sites vs. Origins
Before we dive into cookie dynamics, let's define a couple of terms and related concepts: site and origin.
A site is broader than an origin, and is usually pinned to what most people think of as a domain, such as bitsight.com or bitsight.co.uk. (The latter is provided to illustrate that domains can be more than just the top-level domain, e.g.,.com,.net, etc, and one level below; .co.uk is considered a multi-part top-level domain, or TLD.) For example, blog.bitsight.com and login.bitsight.com would be considered the same site—as long as they use the same scheme or protocol (e.g., https or http).
When we're talking about cookies, they default to site (not origin) dynamics, although as we'll discuss later, you can control the behavior with the SameSite option when a server sets cookies.
An origin is more restrictive than a site in that all three parts of a URL must match, and is simpler in that regard:
- The scheme or protocol, e.g.,
http, https, ftp,etc. - The port, which is often assumed, such as
443forhttpsand80forhttp, but can be explicit, such as inhttps://www.bitsight.com:443 - The domain, which must match exactly. In the site example above,
blog.bitsight.comandlogin.bitsight.comare not considered the same origin. In fact, a subdomain is not considered the same origin, andwww.bitsight.comandbitsight.comare not the same origin, even though they often refer to the same content, usually by a CNAME or redirect.
The Same-Origin Policy (SOP) applies by default to scripts, but like the SameSite directive for cookies, the SOP can be modified by the server to allow cross-origin functionality.
For detailed examples of SameSite and same-origin, check out this PortSwigger article.
Why Do SameSite and Same-Origin Policies Exist?
SameSite and Same-Origin policies restrict access to sensitive data, such as cookies, to only the sites that sent them in the first place. For example, if you login to a banking site and it sends a cookie containing a session id that identifies you and confirms that you've successfully authenticated to the site, you don't want unrelated or third-party sites from gaining access to that cookie. The consequence is the third-party site, potentially controlled by a threat actor, could make a request to your banking site using the session id, and transfer funds without your authorization.
Third-party sites are common in modern website composition. Even though you might initially browse to https://www.bitsight.com, embedded in the content are a number of additional requests for images, style sheets (which define styles and rules for rendering the web page, including fonts and colors within the content), JavaScript, etc. Any or all of these elements may be requested from a site that's not related to the original request. For example, images may be located on https://library.freeimages.net; JavaScript may be imported from Google's library repository. This is what each might look like this in the HTML content:
<img src="https://www.w3schools.com/images/w3schools_green.jpg" />
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.7.1/jquery.min.js">
Imagine these are embedded in your bank's website. You wouldn't want the session id cookie—or other sensitive cookie data—to be sent to the sites that are the source of the image or JavaScript library.
What Can Attackers Do With Cookies?
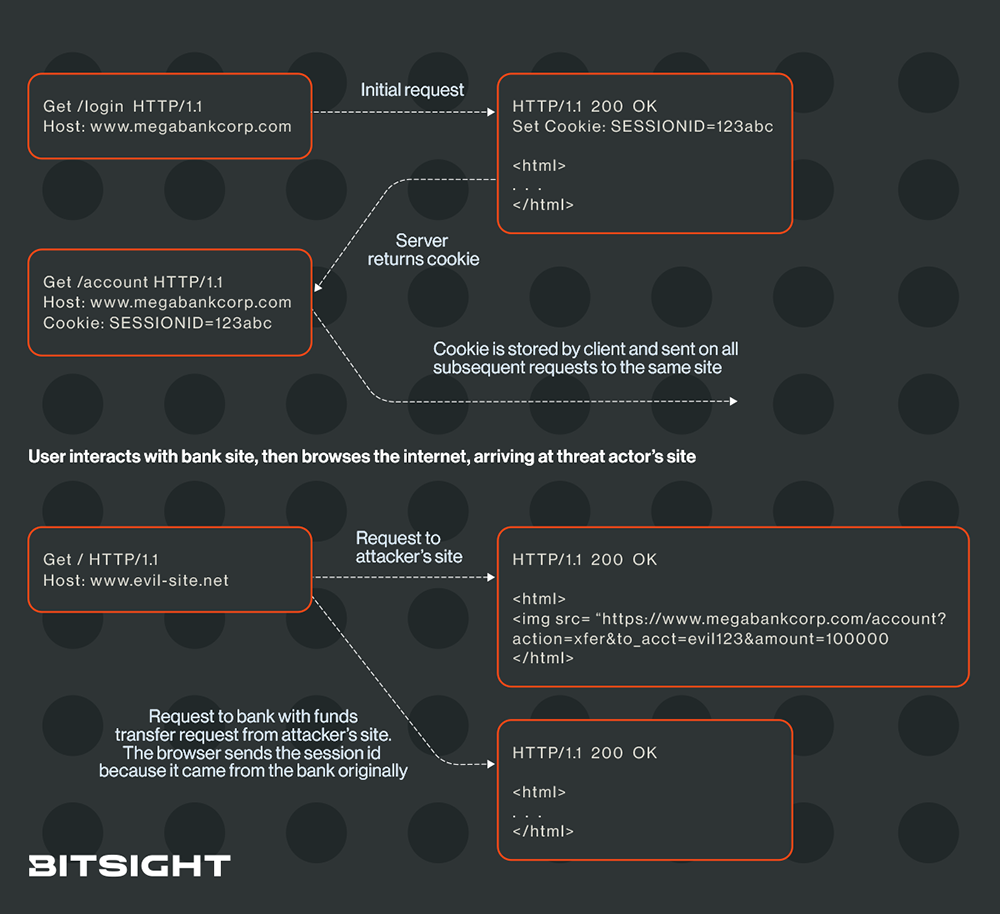
Expanding on the example above, let's say you're logged into your bank account and your browser has a session id stored in a cookie from www.megabankcorp.com. By default, any time you visit any host or subdomain of megabankcorp.com, your browser will provide the session cookie back to the website. (For those who already understand the concepts to this point and beyond, we'll dive into SameSite options and default browser behaviors in a bit so hang tight.)
You finish your banking business and move onto browsing other websites and run across a link that sounds interesting. Perhaps it was planted on a legitimate website, a subreddit, or it was embedded in an email. The site name seems legitimate, but what a link says and where it goes can be vastly different, as you'll remember from any of your phish prevention training. But a moment of inattention and you end up at www.evil-site.net, where, embedded as what looks like a URL to an external image is actually a link to your bank's website with a request to transfer $100,000 to the attacker's bank account. This is know as Cross-Site Request Forgery (CSRF or XSRF) and looks something like this:
<img src="https://www.megabankcorp.com/account ?action=xfer&to_acct=evil123&amount=100000">
Note that the above may be wrapped for readability. The components are:
<img src …>is an HTML tag instructing the client to retrieve an image from the location indicated in src. HTML tags are enclosed in angle brackets, beginning with < and ending with >https://www.megabankcorp.com/accountis the URL for the bank's website and path to the page which shows your account balance and allows you to conduct transactions such as transferring funds. action=xfer is a parameter telling the website what kind of account action you wish to perform. In this case xfer is a funds transfer.to_acct=evil123is a parameter telling the website where to transfer the funds, in this case evil123, which is the attacker's bank account or routing number (yes, I realize it's not formatted as either, this is an example after all).amount=100000is a parameter telling the website how much money to transfer—$100,000!
Note that there are no standards for which parameters must be included in a request; it's up to the web application developer to define the names of the parameters and the values. However, the following are HTTP standards:
- ? (question mark) is used to separate the URL and path from the parameters
- = (equals sign) is used to separate the parameter name, or key, from the parameter value
- & (ampersand) is used to separate parameter key/value pairs from each other
Here's what the attack looks like visually:
Also note that the request in this example uses a parameterized query, which implies the use of the GET request method of HTTP. This attack could also be accomplished using other request methods, POST being the most likely, and will depend on what the bank website expects. Don't worry if you don't understand what request methods are, or the POST request method in particular—I'll cover that, as well as how logging out works, in the next installment.


