Web Application Security for DevOps: The Fundamentals
Tags:


Writing reliable and user-friendly web applications takes significant knowledge, skill, and experience; writing secure web applications introduces a whole new level of complexity.
To write web applications you need to understand not only HTML, CSS (cascading style sheets), JavaScript, and how different browsers render content, but also pull in different libraries such as jQuery and Google APIs. Each of these introduces the potential for vulnerabilities, whether it's in the main code or that from a third-party. Hopefully most web developers have undergone some training on secure coding practices, such as using stored procedures to make database calls instead of concatenating strings into a SQL statement, which opens the potential for SQL injection attacks.
Instead of trying to eat that entire elephant in this blog series, I'm going to focus on operational security, such as web application headers and defenses against attacks such as cross-site scripting (XSS), cross-site request forgery (CSRF), and vulnerabilities in included libraries. Most of what this series will cover are techniques and directives to protect the data and client, although some provide protection for the server that the application runs on.
This Series Is For You, Whether You're a Technical Expert or Not
This series is intended for readers with all levels of experience, and will start with some introductory concepts, such as an intro to the HTTP protocol and how cookies work. The more advanced readers may opt to skip the first installment; however, I learned a fair bit while doing the background research for this series and I suggest you at least skim this post before moving on to the next article. Of course you can always start wherever and come back any time you like.
Here are the range of topics this series will cover:
- HTTP requests and responses
- Cookies
- Server Name Indication (SNI), load-balancers, Content Delivery Networks (CDNs), and proxies
- Basic attacks, including:
- Cross-Site Request Forgery (CSRF/XSRF)
- Man-in-the-Middle (MItM)
- Reverse tabnabbing
- Vulnerabilities and insecure practices, including:
- HTTPs to HTTP redirects
- Authentication over HTTP
- Mixing encrypted and unencrypted content
- Sensitive information exposure in URLs (e.g., session tokens)
- Directory listing
- Information exposure with internal server errors
- Using libraries with known vulnerabilities
- Secure practices in web applications, including:
- Cross-Origin Resource Sharing (CORS)
- Subresource Integrity Check (SRI)
- Security headers, including Content-Security-Policy (CSP)
So with that in mind, let's start with the basics.
HTTP Requests and Responses
The HTTP protocol is text-based and the common commands are easy to understand. Clients will make requests for pages on a web server, indicating:
- The path of the page (e.g., /blogs/web-app-security/)
- The HTTP protocol (normally HTTP/1.1)
- The hostname of the server (e.g., blog.bitsight.com)
- Headers and cookies, which we'll tackle later
The client in most web interactions is a browser and the server is the web server that's delivering the content; however, the client could be an app, a scanning engine, or any number of non-user devices, while the server might be a device you're managing, such as a router or IoT device. Because the HTTP protocol is text-based, you can act as a client using most terminal emulator apps such as telnet or SSH to make requests to websites—as long as they don't use network encryption1. You may need to install an app: telnet is no longer included on Macs and netcat, my personal favorite, isn't installed on either Mac or Windows.
For now, feel free to try the following using telnet or similar. I'll use netcat, which uses the command nc. nc is typed at the command line (Terminal for Mac users, Command Prompt for Windows users, and if you use Linux you already know what a command line is), while the remaining commands are typed within the session, with no prompt.
nc bitsight.com 80 Connection to bitsight.com port 80 [tcp/http] succeeded! GET / HTTP/1.1 Host: bitsight.com
Note that the blank line after the line starting with Host: is intentional; it signals to the server the end of commands and options, and that the server should respond.
There are many response codes you may get from the server, where 200 OK is the one that signals that the command was successful and the server is returning what it's supposed to. In this case you'll see a 301 Moved Permanently response, which signals the browser to make another connection to the URL in the Location response header (it's a redirect). Feel free to read through the rest of the headers, although we'll only cover a few in this blog series. You're a smart human, otherwise you wouldn't be reading this blog post, so enjoy the research assignment.
HTTP/1.1 301 Moved Permanently Date: Fri, 06 Sep 2024 20:31:58 GMT Content-Type: text/html Content-Length: 167 Connection: keep-alive Cache-Control: max-age=3600 Expires: Fri, 06 Sep 2024 21:31:57 GMT Location: https://www.bitsight.com/
<html>
<head><title>301 Moved Permanently</title></head>
<body>
<center><h1>301 Moved Permanently</h1></center>
</body>
</html>
Also note that the blank line after the response headers signals the start of the returned content. In this case it's a simple HTML document letting you know the site is located elsewhere. The browser should redirect to the final page so quickly you won't even see the content in a browser, but remember that not all web accesses are done with web browsers.
Finally, your telnet or netcat session (or whatever you used) will probably still be waiting for you to enter another request. That's because HTTP version 1.1 provides persistent connections to avoid opening and closing TCP sessions for each request, which HTTP version 1.0 used to do and was both inefficient and would often clog up firewall session tables. Just close the client app you're using, hit Ctrl-C for netcat, whatever it takes to bail out of the session.
Server Name Indication
You'll note in the request above the Host: field. One of its purposes is to identify to the web server which host to which you're trying to connect. The reason is that a single server, using a single IP address, can host a number of distinct websites. The Host: field lets the server know which of the multiple websites to serve content from; that's Server Name Indication, or SNI.
Think of web servers as having folders on a hard disk—which is often how content for a web server actually works. Web servers that only serve up content for a single website might only have a /www folder and associated subfolders, while servers that host multiple websites have folders for each. Imagine a single server hosting two domains, bitsight.com and someothersite.com:
- when you specify
Host: www.bitsight.com, the web server is configured to return webpages from the/websites/bitsight_comfolder; - when you specify Host: www.someothersite.com, it's configured to return web pages from the
/websites/anothersitefolder,.
I purposefully made the content folder for the latter website not mirror the domain name; there's no hard rule that the content folders must use the domain name; the mapping of hostnames or domain names is arbitrary and at the discretion of the system administrator.
Cookies
Despite the fact that HTTP 1.1 supports connection persistence, each request is treated as new and has no association with any previous request. If you visit a login page, for example, and submit your username and password, that's one request and response. (Actually it's likely many requests and responses; each image, ad, and other page elements that may not directly render in the browser, are each separate HTTP requests and often to sites other than the one you're browsing. More on that later.) Once you're logged in and brought to your bank account or airline booking main page, how does it know that you've previously authenticated and it should return information relevant to your account?
Cookies, of course.
Cookies are merely headers that are returned from the server, in our example upon authentication, and stored by the browser. When the browser makes a subsequent request to the same site, it includes the cookie in its headers so the server can tie that request to your authenticated session. This is what it looks like behind the scenes:
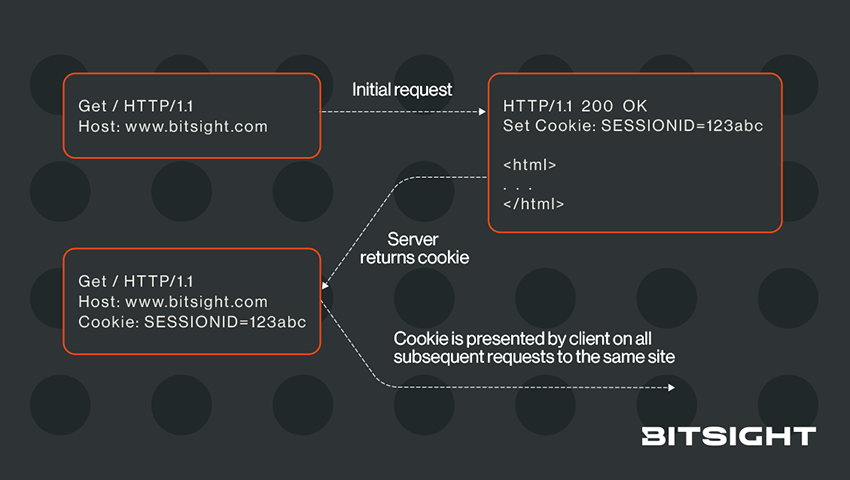
Important points:
- Servers set cookies
- Browsers send the cookie(s) back to the website that set them—not to other other websites
The obvious question then is, when you navigate away from a site that set a cookie, how do browsers know which site set the cookies in the first place? And what constitutes the same site? That's a complicated question that we'll tackle in the next installment.
1You can interact with sites that use encryption, e.g., HTTPs, but you need to use an app that sets up the TLS connection first, such as OpenSSL. That's beyond the scope of this blog series, although I may cover it in a future post.