Web Application Security for DevOps: Anti-CSRF and Cookie SameSite Options


This is a continuation of our series on web application security. If you haven't already read through parts 1 and 2, this is a good time to go back. If not, let's move on and answer the question left hanging during our last installment: what are request methods, including the POST request method, and how does logging out of a website work when it comes to cookies and session IDs? Let's also tackle the more important issue of how to combat cross-site request forgery (CSRF) attacks.
Key takeaways
- CSRF attacks can succeed in both GET and POST HTTP requests
- Using tokens in forms to thwart CSRF attacks
- Using the Set-Cookie SameSite option to thwart CSRF attacks
- Why you should always logout of websites, every time
HTTP request methods
We've already analyzed what a GET request method looks like in part 1 of this series. It turns out there are nine (9) methods, of which five (5) are the most common. These five can be associated with the CRUD operations for managing data in a database:
We only need to understand GET and POST for the purposes of this article; however, if you write web applications you should take the time to fully understand all of the request methods.
While GET passes any parameters in the URL itself—known as query parameters—the POST method passes parameters in the body of the request. Here's an example GET request with parameters:
GET /app/spm/companies/search/?term=bitsight.com HTTP/1.1
Host: service.bitsighttech.com
We discussed query parameters briefly in part 2 of this series, but as a refresher:
- The path to the page starts after the GET request up until the question mark (?). In this example it's /app/spm/companies/search/
- The question mark (?) is a separator between the path and parameters
- The parameters are a series of key/value pairs, with an equals sign (=) separating the key from the value. In this example the key is term and the value is bitsight.com
- Multiple key/value pairs are separated by an ampersand (&), as in term=bitsight.com&industry=Technology
There are two issues with GET requests with parameters:
- There's a limit to the URL length that browsers and servers will accept. The length varies by browser and server, but generally a URL should be less than 2,048 characters. There are many cases where there are many parameters, such as a list of finding identifiers, that could force the URL to exceed 2,048 characters.
- Even when using encryption (i.e., TLS over HTTP, or HTTPs), the URL itself is not encrypted and can reveal sensitive information. An attacker may be able insert themselves into the request path (e.g., through a man-in-the-middle attack or sniffing network data) or if they gain access to web logs, which capture the request URL.
The POST method sends parameters in the body of the request, which has no practical limit and is encrypted when using HTTPs. Typically the parameters are passed as a JSON or XML document. Here's the above example using the POST method and with additional parameters:
POST /app/spm/companies/search/ HTTP/1.1
Host: service.bitsighttech.com
{
"term": "bitsight.com",
"industry": "Technology",
"limit": 5
}
For completeness, although we're not going to concern ourselves with them, there are also path parameters, which can be included in all request methods. They're parameters included as part of the URL document path. For example, the application could require the company name be included as a path parameter instead of a query parameter. Using the example above, here's what it might look like:
POST /app/spm/companies/search/bitsight.com/ HTTP/1.1
With the background knowledge of how HTTP requests work, let's revisit our CSRF example from part 2 of this series, but in the context of a POST method.
CSRF in POST requests
If you remember from our CSRF attack using the GET request method, the attacker only needs to know how to compose a URL containing the parameters expected by your bank's online web app in order to transfer your funds to their account. They don't need to know the session ID because it's sent automatically in the same site requests.
It's not as simple for the attacker with the POST request method because your browser sends parameters in the body of the request. Those will usually come from form fields on a web page that accept user input, such as the account to which you want to transfer funds and the amount of funds to transfer. There are also buttons that the user must click to submit the form fields or cancel the action.
The underlying HTML has a form, as well as input fields that may look something like:
<form action="/transfer" method="post">
<input type="text" name="to_acct" />
<input type="text" name="amount" />
<input type="submit" value="Submit" />
<input type="button" value="Cancel" />
</form>
Here's where JavaScript stops being your ally and defects to the dark side, assisting attackers. Assuming they can lure you to their evil web page, the page can host hidden input fields and contain a snippet of JavaScript code that automatically submits the web page. Here's what the web page might look like:
<html>
<body>
<form action="https://www.evil-site.net/xfer/" method="POST">
<input type="hidden" name="to_acct" value="evil123" />
<input type="hidden" name="amount" value="100000" />
</form>
<script type="text/javascript">
document.forms[0].submit();
</script>
</body>
</html>
If you've never examined HTML source, here are some basics:
- Statements that instruct the browser to render content in a special way, such as input fields and buttons, are called tags and are enclosed with angle brackets (
<and>). Multi-line tags start with a directive, such as<form>and end with the same statement with a slash (/) immediately after the opening angle bracket, such as</form>. Some tags are single-line and can be enclosed within a single pair of angle brackets, with the slash preceding the closing bracket, such as<input type="text" name="to_acct" />. - The
<html>and<body>tags (and their closing pairs,</html>and</body>) enclose HTML and the body of the HTML, respectively. In addition to the body, HTML documents can also have header elements. - The
<form>tag encloses the input tags (aka, form fields or elements) that will be sent to the server when the submit button is clicked. The names and values of the form elements are sent to the server, typically via a POST operation. You can have multiple forms on a web page. - There are many types of input tags. The relevant ones to the example above are:
- The
textinput, which is just an area where you type something such as in a search field. Thevalueoption contains the default value that's loaded into the field and will contain the user input if they edit the field and submit the form - The
hiddeninput field is like atextinput field, but the user can't view or change the value - The
buttoninput is the general purpose button. Thevalueoption sets the label for the button. - The
submitinput is the same as the button input but causes the form to be submitted.
- The
The two input fields are hidden and contain the attacker's account number and the amount to transfer to their account; the JavaScript submits the form immediately after the document loads, with no need for the user to interact with the web page.
Anti-CSRF using tokens
The accepted method of combating CSRF is a combination of using secret tokens and limiting to which website cookies are sent.
Let's start with anti-CSRF tokens. They're random strings usually provided as a value to a hidden input field. Most CSRF attacks involve conducting some activity on an interactive website, such as transferring funds on a banking website or adding a mobile phone number to your account to which to text login confirmation codes.
Hidden fields can be used to prevent CSRF attacks by populating it with a random string that the server knows and can verify that the form was submitted by the authenticated user and not an attacker. Here's an example:
<input name="CSRFToken" type="hidden" value="SomeLongAndRandomString" />
It's important to clearly distinguish between the behavior cookies and form fields:
- Cookies are automatically sent by the browser to the same site that set them, and are sent as headers
- Form fields are sent by the browser when the user submits the form (or as we've seen, JavaScript mimics the user submitting the form), and are sent either in the body of the request if the method is POST, or in the URL if the method is GET (which is not recommended for sensitive information, as mentioned earlier)
Using form fields forces the attacker to guess the value of the CSRFToken field. (Note that the name of the field can be anything, but don't rely on that as a form of security obfuscation because the attacker can get the name of the field by navigating to the web page and viewing the source HTML.)
A new anti-CSRF token should be generated for each form, be long and random enough to be practically unguessable by an attacker, and last for the duration of the user session. The server should maintain a list of session IDs and anti-CSRF tokens to be able to validate each submission and reject those for which there's a mismatch.
In order to combat brute force or guessing attacks OWASP and CWE recommend 128 bits of entropy, or 20 characters including all printable ASCII characters, for session IDs, under which rubric anti-CSRF tokens fall.
Anti-CSRF using the Set-Cookie SameSite option
The second anti-CSRF mechanism is to restrict when the session ID cookie is provided to the site that set it. If you recall from part 2 of this series, site doesn't mean the specific website host that set the cookie, but any host within the same domain. This can be too relaxed for security purposes or too restrictive for operational purposes.
Going back to our example from part 2 of this series, here's what a successful CSRF attack looks like:
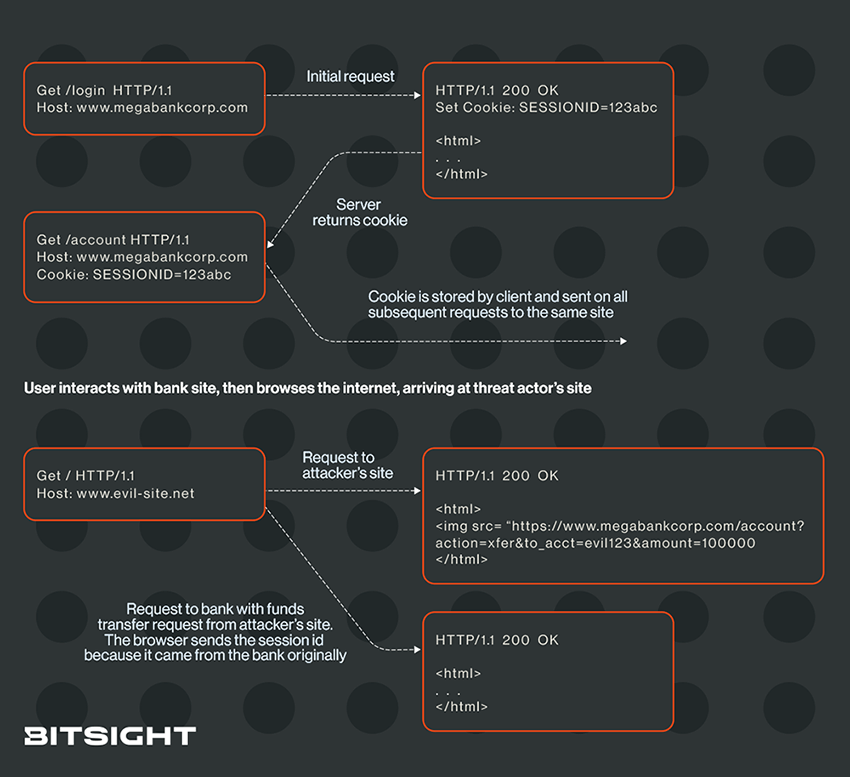
If we want to prevent the browser from sending the session ID cookie to www.megabankcorp.com when the victim naively browses to the attacker's site, www.evil-site.net, we can use the Set-Cookie directive, SameSite=Strict.
Set-Cookie: SESSIONID=123abc; SameSite=Strict
With the option set, the browser will only send the cookie to the site it was set by if:
- The user types the URL into the address bar and navigates directly to the site
- The user refreshes the page (which is essentially the same as if the user types the URL into the address bar)
- The user follows a link to a page from within the same site
- An
<iframe>is hosted on the same site - A JavaScript
fetchrequest is made from the same site
Remember that site in this context means the same scheme or protocol (e.g., http, https, ftp) and domain (e.g., bitsight.com or bitsight.co.uk); different hostnames within the same domain or subdomains are considered the same site (e.g., blog.bitsight.com and login.bitsight.com). One way to think about this is that SameSite=Strict informs browsers to restrict sending cookies in cross-site requests.
If the server doesn't set the SameSite policy, the default is up to the browser. Most browsers default to SameSite=Lax, in which browsers will only send cookies to a site if:
- The user types the URL into the address bar and navigates directly to the site
- The user refreshes the page
- A link on another site makes a request to the site that set the cookie (aka, cross-site) using the
GETrequest method AND resulting from a user action, such as clicking on a link - An
<iframe>is hosted on the same site - A JavaScript
fetchrequest is made from the same site
The perceptive user will notice that the conditions are almost the same as for SameSite=Strict; however, SameSite=Lax allows cookies to be sent to the site from links on other sites (cross-site) if the request method is GET and is initiated by the user. That means if a user clicks on a link or submits a form on www.evil-site.net that leads them back to www.megabankcorp.com, the cookie that was set on www.megabankcorp.com will be sent to it, enabling a CSRF attack to succeed—as long as the request method is not POST.
I don't want to gloss over the condition that the action must be initiated by the user, which is also called top-level navigation because it changes the URL in the navigation bar; whereas, links embedded in web pages, such as images, don't change the navigation bar. Most of the time top-level navigation is initiated by the user; however, there are mechanisms that can either imitate a user action, such as the JavaScript command document.location=URL, where URL is any valid URL. Redirects also change the URL in the navigation bar.
The reason SameSite=Lax is the default, which seems counterintuitive from a security point-of-view, is that many web pages are composed of content from many sites that need to share cookies to maintain state. SameSite=Strict breaks many sites—unless they're designed with secure sharing in mind, which we'll cover in the next installment of this series.
There's also a third SameSite option: None. It's not recommended so I won't cover it here.
Anti-CSRF using the Referer header
A less effective method of preventing CSRF attacks is to use the HTTP Referer header to validate that the request was submitted from a trusted site. By default, browsers will add the Referer header (yes, referrer is misspelled in the HTTP spec, and lives on in operation as a typo) to requests that originate from a page, typically when the user clicks a link or submits a form.
If an attacker attempts to conduct a CSRF attack, the user's browser would add a Referer header to the request letting the destination site, www.megabankcorp.com, know that the site from which the request was made is www.evil-site.net. If Mega Bank's web application developers are security-conscious, they design the server-side code to reject requests from sites that aren't explicitly allowed.
However, there are known methods to elicit the browser to not present the Referer header to the destination website. Further, developers may make mistakes in parsing the referring URL. As a result, using the Referer header should not be counted on as a primary anti-CSRF mechanism.
Cookie expiration and logout mechanisms
Let's wrap up the discussion of cookie mechanics with how to prevent browsers from sending cookies, for example after the user logs out of a website.
When a server sends a cookie it can tell the client when to expire it. Here are examples:
Set-Cookie: SessionID=123abc; Expires=Sun, 25-Dec-24 12:00:00 GMT
Set-Cookie: SessionID=123abc; Max-Age=3600
The first line tells the client the date and time when the cookie expires; the second is how long the client should retain the cookie in seconds (3600 seconds is one hour).
The server can update a cookie any time the client visits the website, including setting a new expiration date/time or Max-Age. It simply sets the cookie with the same name to a new value and optional parameters, such as Expires or Max-Age.
This is how you delete a cookie: set the Expires to a date that's already past or a Max-Age of 0 or a negative value. It's also good practice to change the value of a cookie you want to delete to a neutral value, such as "deleted".
However, remember that you don't control the client, and an attacker can ignore cookie expiration periods. The most important operation in expiring cookies is to remove them from the server side so that, even if an attacker sends a cookie that's expired or aged out, the server knows to ignore it. The mechanism for deleting server-side cookies is dependent on the server software and coding framework; consult your system, language, or framework reference for details.
Server-side cookie management is particularly important when there could be material consequences, such as banking or health information websites. It's also important for users to understand that it's critical to logout of websites after they've completed their business.
Next up
In the next installment of this web application security series I'll show how Cross Origin Resource Sharing (CORS) and Subresource Integrity Checks (SRI) can enable cookies and other content to be securely shared between sites with different origins.
