Challenges in Automating and Scaling Remote Vulnerability Detection
Tags:

Introduction
When a new major CVE gets released, cybersecurity companies race to discover ways of detecting the new vulnerability and organizations scramble to determine if they are impacted or not. Developing high-confidence techniques to scan the public-facing Internet assets for newly published vulnerabilities can potentially take weeks or even months as vulnerability researchers discover and test various detection methods. While the security ratings use case cannot tolerate false positive vulnerability detections; the high latency on producing such high-confidence methods diminishes the value of that data for exposure management use cases, where users want any indicators of exposure as soon as possible, including less reliable ones. In this blog post, we will cover investments that Bitsight is making to greatly scale out our vulnerability coverage and highlight vulnerability exposures to our customers in record time through automation.
Current State of Remote Vulnerability Detection Research
First, we need to go over the current state of remote vulnerability detection research so we can break it down piece by piece and show how we can automate this process and demonstrate that what would otherwise be a straightforward process is rife with challenges. For the purposes of this blog post, I will only focus on remote detection of vulnerabilities and won’t be covering detection when you have local or internal network access to devices.
When a new vulnerability comes out, vulnerability researchers look at public information such as released patches, PoCs, blog posts, and several other resources to determine what the vulnerability actually is and how to go about detecting it. From this information gathering process there typically emerges two possible paths of remote detection:
- Detecting something unique about the vulnerability or the patch itself
- Using product version information to determine if a device is vulnerable
Option 1 detects the vulnerability directly, either through leveraging an exploitation technique or detecting something unique about the vulnerability or the patch. Unless you are a threat actor or you don’t care about the moral/legal aspects of it, then exploitation or anything close to exercising a vulnerability is off limits when performing scans across the Internet. Instead, we must identify unique elements specific to that vulnerability such as a 400 response on patched versions but a 500 response on unpatched versions when navigating to the vulnerable webpage. This method of vulnerability detection tends to have a high level of confidence in whether a system is vulnerable or not. The downside is identifying these unique elements and writing/testing code for the remote vulnerability detection is time consuming and potentially won’t yield any results for your efforts.
This brings us to option 2, which is to identify the version of the product and determine if it falls within the vulnerable version range of the CVE we are trying to detect. Not only is this process significantly easier but it is appreciably quicker. The process for this detection method is seemingly straightforward:
- Determine how to detect the specific software product and its versions that are of interest, often called product fingerprinting.
- Find the CVEs that affect that particular product.
- Take the fingerprinted versions and check if they fall within the vulnerable version range or not. Assuming the CVE doesn't require any special permissions or configurations and no mitigations can be applied, then we can assume a system is vulnerable if its version falls within the vulnerable version range.
- If it does, then we can say the asset is vulnerable to a particular CVE
The benefit to this process is that once you have the product fingerprint, it is typically quick to check if a system is vulnerable or not. Option 2 allows us to quickly determine which systems are likely exposed to a vulnerability and help customers prioritize checking those systems further and it allows some level of vulnerability detection while option 1 is being pursued for a higher confidence check.
However, there are several reasons why the above is not quite as straightforward as it seems. This detection method does not achieve the same confidence level as option 1. CVE’s also come with various special conditions such as requiring a specific server configuration that a simple version check is not able to determine. Additionally, detecting product versions remotely is not always possible and can be time consuming and difficult in most cases.
In this blog we are going to discuss the challenges of product fingerprinting and how we can automate a large portion of the remote vulnerability detection process.
Product Fingerprinting
The first part of this system is arguably the most important, because if you aren’t detecting products or versions correctly then it doesn’t matter what the rest of your system does because it is going to be wrong, in short: garbage in, garbage out. We are not going to spend a ton of time on the fingerprinting process. There are open source tools available that can accomplish this task if you feel up to rolling your own.
Here at Bitsight, we use our own proprietary scanning engine called Groma which scans for a wide range of products and vulnerabilities. When our scanning engine detects a specific product, it also scans for vulnerabilities affecting that product using custom detection techniques that were created by our vulnerability researchers using option 1 that I mentioned at the beginning of the article. In addition to the product information, these high confidence vulnerability detections can be leveraged to determine the presence of other vulnerabilities. Groma uses the CPE framework to record products and versions it finds, allowing us to leverage vulnerability databases, such as the National Vulnerability Database(NVD), that record CPEs. NVD also contains the relationships between CVEs and CPEs so you can look up which CVEs apply to a specific CPE.
Mapping Vulnerabilities
Mapping CPEs to CVEs is not as straightforward as it initially seems. We wish it was as easy as taking version 1.0.0 of product A and then looking for all the CVEs that have product A version 1.0.0 listed as vulnerable. Unfortunately, the CPE framework was designed to cover a wide range of use cases, meaning you have to account for every one of those use case when doing the mapping. It’s a lot of work.
NVD uses 2 different kinds of CPEs for CVE configurations. The first is a CPE that applies to a single product and a single version, which is an easy comparison for us because it either is or it isn’t an exact match. The image below is what these CPEs look like on NVD

The second type of CPE is one that applies to a single product and a range of versions. Below are images taken from NVD of what each this type of CPE looks like
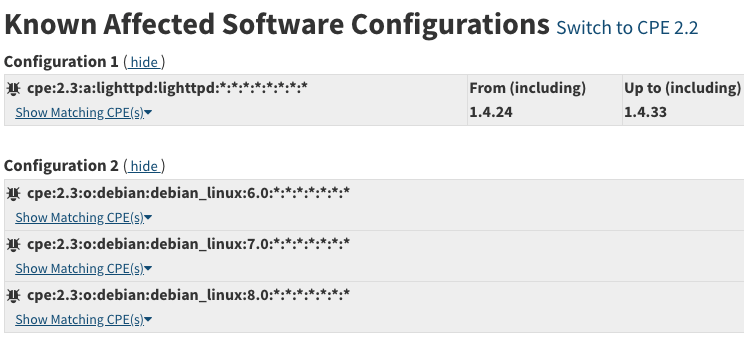
This second type of CVE is more difficult because we need to implement our own version comparison framework to accurately determine if a CVE applies to a specific version. For most products this is pretty straightforward, but for products such as Cisco IOS this can be a headache. Version comparison is often complicated by the fact that version ordering can be ambiguous, such as Atlassian Bitbucket version 7.6.19 is actually a newer version than 7.22.0. Companies will also switch the version scheme such as Adobe Coldfusion going from version 11.0 to version 2016. Another example is CVE-2018-15377 which has the CPEs shown below:

How would you go about comparing these CPEs together without explicitly writing code for the Cisco IOS product line? Products such as this make version comparison not trivial and so these edge cases need to be identified and either excluded from the data or a custom version parser needs to be created to handle these cases.
While we are on the topic of edge cases, I should warn you that NVD and other vulnerability databases are filled with data quality issues and errors. The list is too long to cover here but the CVEs that makeup NVD and other vulnerability databases are sometimes reported by product vendors such as Microsoft, Apple, Google, etc and sometimes created by NVD. There is supposed to be a standard way that every vendor reports new CVEs but unfortunately very few organizations follow that standard and every vendor tends to report CVEs and CPEs how they like. This leads to differences in the data where one vendor reports cpe:2.3:o:microsoft:windows:10 and another reports it as cpe:2.3:o:microsoft:windows_10 and some vendors have very thorough descriptions whereas other vendors just put ‘unknown vulnerability’ in the description. Essentially, it is important to perform some data quality checking instead of just trusting the data in NVD.
Now that we covered those warnings, let’s assume that we have a version comparison system that works well and we have handled the data quality issues in the vulnerability databases. We will cover 3 different types of mapping processes. The first is a simple version lookup mapping. The second we will call dependency mapping, which maps multiple CPEs together to CVEs so we can have a higher confidence that a target system is vulnerable. Lastly, we have CVE clustering which takes the version range that a CVE applies to and determines what other CVEs apply to that same version range. Put another way, through our vulnerability scanner if we detect that system X is exposed to CVE-2020-1234, which applies to version 1.0.0 of product A, then we can say system X is also likely exposed to CVE-2020-4321 which applies to versions 0.0.9, 1.0.0, and 1.0.1.
(Not so) Simple Version Lookup
In the case where a particular version of a product is vulnerable, with no other dependencies, this mapping process is pretty straightforward. We can use our product fingerprinting framework to produce CPEs and lookup the CPE in the database to find the applicable CVEs. You can also do this quite easily using NVDs API. If we fingerprinted Microsoft Windows 10 update 1511 which has a CPE of cpe:2.3:o:microsoft:windows_10:1511:*:*:*:*:*:*:* then we can look it up in NVD at https://services.nvd.nist.gov/rest/json/cpes/2.0?cpeMatchString=cpe:2.3:o:microsoft:windows_10:1511:*:*:*:*:*:*:* which will return the 3 applicable CVEs. Again, I want to emphasize that this seems simple, but in fact is complicated by the CPE framework and the fact that versioning is not exactly straightforward, but with some caution this scales better than doing it CVE by CVE.
Another layer of complexity with Dependencies
Some CVEs only apply to systems running with specific configurations. For example, CVE-2023-27497 is a vulnerability affecting SAP Diagnostics Agent running on Windows. This means you not only need to fingerprint SAP Diagnostics Agent but also that it is running on a Windows Operating system and both of those CPEs together mean a system is vulnerable to the CVE. CVEs that have this dependency condition appear like the following on the NVD website
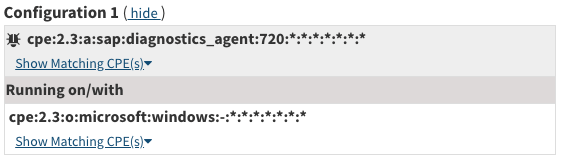
In order to make a mapping that covers these types of CVEs, we add a list of dependency CVEs to the list from the Version Lookup section. This makes it so when we look up a CPE we get a list of applicable CVEs and also a list of dependent CVEs that we need to provide additional information for. In our example, we would look up cpe:2.3:a:sap:diagnostics_agent:720:*:*:*:*:*:*:* and get a dependent CVE list back that contains CVE-2023-27497. We would then have a lookup of dependent CVEs, where each CVE has a list of required CPE combinations. We would then check if any of the other CPEs we gathered from our target system fulfill the CVEs criteria. Below is a how a simple dictionary would look for a system like this:

This allows us to look up our detected CPE for a given CVE and determine what other CPEs need to be present for the system to be marked as vulnerable to the CVE. In this case if we detected it was a windows 10 computer running SAP diagnostics agent version 720 then it would be vulnerable to CVE-2023-27497.
Again this is complicated by the vagaries of the CPE framework and the fact that because we now have multiple products to check our fingerprinting must be able to reconcile this logic. Again doable but adds another layer of complexity for vulnerabilities with this type of dependency.
Direct CPE Matching
CVE clustering is meant to provide us with a way to map additional vulnerabilities from our high confidence vulnerability scanners without having to spend all the time and effort implementing a detection effort specifically for those vulnerabilities. It also allows us to automate the vulnerability detection process for products where we are unable to determine the product version. The basic premise behind CVE clustering is if a system is exposed to a CVE then it is highly likely to also be vulnerable to any CVE that applies to the same version ranges.
This process is simple: if a new CVE-X contains all the CPEs of the pre CVE-Y within its vulnerable version range, then if a system is vulnerable to CVE-Y then they are vulnerable to CVE-X. Put another way, if CVE-Y’s version range encompasses CVE-X’s version range then exposure to CVE X implies exposure to CVE Y. The resulting mapping is then CVE X and a list of all the CVEs that have an encompassing version range for the same product.
The paragraph above glosses over some things. We of course have to worry about dependencies above, but “encompases” is doing a lot of work. CVE-X may have a different version range, but careful checking has to be done to ensure that narrower range is totally subsumed by CVE-Y.
How much did this actual scale?
You may be saying, this sounds great and all but how much of an impact can this system really have? Having done the hard work to address all the challenges above, we have compiled some statistics to show the impact of this system on our vulnerability detection here at BitSight. These stats were created at the end of July in 2024 and we are rapidly growing these numbers as time goes on.
At Bitsight, we have been able to scale our vulnerability coverage to cover 25% of the CISA KEV list over the past year.1 This is largely attributable to the work done by Bitsight’s Vulnerability Research team with this mapping process providing a few additional CVEs. The mapping process has been more impactful in scaling Bitsights overall vulnerability coverage. The mapping process has helped to increase Bitsight’s overall vulnerability coverage by 300% over the past year.1
It is important to highlight that Bitsight has spent a painstaking amount of effort to ensure our vulnerability data is accurate and can be relied upon as a high quality signal of exposure. A few of our competitors may use a similar approach to achieve increased vulnerability coverage but they often fail to eliminate noise and false positives in the data. This leads to untrustworthy data, which is almost worse than no data at all because you will have to spend a tremendous amount of effort trying to discern the truth from the false positives. Essentially, when comparing vulnerability detection between companies make sure to not only look at the vulnerability coverage numbers but the quality of the vulnerability information.
NVD Fiasco
NIST issued an announcement sometime ago stating that they were no longer analyzing CVEs so they could establish a consortium to help with their workload and set up a system to maintain NVD for the foreseeable future. This led to a lot of speculation and fear in the cybersecurity community as many companies and products depend on NVD as a reliable data source. It was not known how long NVD would take to build this consortium and get back to analyzing CVEs as their backlog built up. Luckily, NVD announced that they will be assisted by CISA and their Vulnrichment program to help in processing CVEs and maintaining NVD. However, there is still a massive backlog of CVEs that will likely take over a year to process and catch up to latest CVEs. This means that CVEs issued during 2024 are potentially missing CPEs, CVE configurations, and other valuable analysis that is required to perform the CPE->CVE mapping. Steps should be taken to handle the unanalyzed CVEs until NVD gets caught up on their CVE backlog. For more detailed information, see the TRACE blog post on Evaluating dependence on NVD.
Conclusion
In conclusion, we can use vulnerability databases with CPE information and CVE configurations to create a mapping of product versions to vulnerabilities. We can take these mappings and attach them to a product or vulnerability scanner that will extract products and their versions or the vulnerabilities they are exposed to. This information can then be leveraged to create an automated way of detecting vulnerabilities, rather than having to manually write code to detect each vulnerability we can use the version information to determine what vulnerabilities a system is potentially exposed to.
In essence, we set out to build an automated system that can automate the detection of a new CVE shortly after release, and using this system of CPE->CVE mapping we are able to achieve that goal and provide early exposure information to potentially affected customers. Overall it’s a complicated process that involves expert knowledge of the associated frameworks and CVEs to be able to scale to any reasonable degree.
One caveat is that product detection needs to be implemented prior to the CVE being released. This is similarly tricky, but there are ways of automatically detecting new products and generating CPEs that we will cover in a future blog post. What’s important here is that it is possible to handle the flood of new CVEs that are created on a daily basis and increase our coverage proportionally without doing everything by hand.
1 I’d note that the particular type of detections we do at Bitsight won’t be able to find everything on the KEV simply because a large portion of those vulnerabilities are client side.



